实践出真知,看我们如何化解DynamoDB的挑战
|
【大咖・来了 第7期】10月24日晚8点观看《智能导购对话机器人实践》
DynamoDB 是 Amazon 基于《 Dynamo: Amazon’s Highly Available Key-value Store 》实现的 NoSQL 数据库服务。它可以满足数据库无缝的扩展,可以保证数据的持久性以及高可用性。开发人员不必费心关注 DynamoDB 的维护、扩展、性能等一系列问题,它由 Amazon 完全托管,开发人员可以将更多的精力放到架构和业务层面上。
本文主要介绍作者所在团队在具体业务中所遇到的挑战,基于这些挑战为何最终选型使用 Amazon DynamoDB,在实践中遇到了哪些问题以及又是如何解决的。文中不会详细讨论 Amazon DynamoDB 的技术细节,也不会涵盖 Amazon DynamoDB 的全部特性。 背景与挑战 TalkingData 移动广告效果监测产品(TalkingData Ad Tracking)作为广告主与媒体之间的一个广告投放监测平台,每天需要接收大量的推广样本信息和实际效果信息,并最终将实际的效果归因到推广样本上。 举个例子,我们通过手机某新闻类 APP 浏览信息,会在信息流中看到穿插的广告,广告可能是文字形式、图片形式、视频形式的,而不管是哪种形式的广告它们都是可以和用户交互的。 如果广告推送比较精准,刚好是用户感兴趣的内容,用户可能会去点击这个广告来了解更多的信息。一旦点击了广告,监测平台会收到这一次用户触发的点击事件,我们将这个点击事件携带的所有信息称为样本信息,其中可能包含点击的广告来源、点击广告的时间等等。通常,点击了广告后会引导用户进行相关操作,比如下载广告推荐的 APP,当用户下载并打开 APP 后,移动广告监测平台会收到这个 APP 发来的效果信息。到此为止,对于广告投放来说就算做一次成功转化。  DynamoDB实践:当数据量巨大而不可预知,如何保证高可用与实时性? 移动广告监测平台需要接收源源不断的样本信息和效果信息,并反复、不停的实时处理一次又一次转化。对于监测平台来讲,它的责任重大,不能多记录,也不能少记录,如果转化数据记多了广告主需要多付广告费给媒体,记少了媒体会有亏损。这样就为平台带来了几大挑战:
最初形态 在 2017 年 6 月前我们的业务处理服务部署在机房,使用 Redis Version 2.8 存储所有样本数据。Redis 使用多节点分区,每个分区以主从方式部署。在最开始我们 Redis 部署了多个节点,分成多个分区,每个分区一主一从。刚开始这种方式还没有出现什么问题,但随着用户设置的样本有效期加长、监测样本增多,当时的节点数量逐渐已经不够支撑业务存储量级了。如果用户监测推广量一旦暴增,我们系统存储将面临崩溃,业务也会瘫痪。于是我们进行了第一次扩容。 由于之前的部署方式我们只能将 Redis 的多个节点翻倍扩容,这一切都需要人为手动操作,并且在此期间我们想尽各种办法来保护用户的样本数据。  DynamoDB实践:当数据量巨大而不可预知,如何保证高可用与实时性? 这种部署方式随着监测量的增长以及用户设定有效期变长会越来越不堪重负,当出现不可预知的突发量时就会产生严重的后果。而且,手动扩容的方式容易出错,及时性低,成本也是翻倍的增长。在当时由于机器资源有限,不仅 Redis 需要扩容,广告监测平台的一系列服务和集群也需要进行扩容。 化解挑战 经过讨论和评估,我们决定将样本处理等服务迁移到云端处理,同时对存储方式重新选型为 Amazon DynamoDB,它能够满足我们的绝大部分业务需求。经过结构调整后系统大概是下图的样子:  DynamoDB实践:当数据量巨大而不可预知,如何保证高可用与实时性?
(编辑:ASP站长网) |

 MySQL IS NULL如何查
MySQL IS NULL如何查 最简单的创建 MySQL
最简单的创建 MySQL 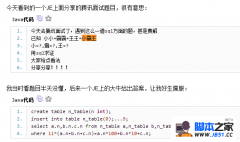 网上看到的给大家分享
网上看到的给大家分享 MYSQL教程MySql 5.6.3
MYSQL教程MySql 5.6.3