实践出真知,看我们如何化解DynamoDB的挑战(2)
|
此外还有:
实践出真知 我们在使用一些开源框架或服务时总会遇到一些“坑”,这些“坑”其实也可以理解为没有很好的理解和应对它们的一些使用规则。DynamoDB 和所有服务一样,也有着它自己的使用规则。在这里主要分享我们在实际使用过程中遇到的问题以及解决办法。 数据偏移 在 DynamoDB 中创建表时需要指定表的主键,这主要为了数据的唯一性、能够快速索引、增加并行度。主键有两种类型,「单独使用分区键」作为主键和「使用分区键 + 排序键」作为主键,后者可以理解为组合主键(索引),它由两个字段唯一确定 / 检索一条数据。DynamoDB 底层根据主键的值对数据进行分区存储,这样可以负载均衡,减轻单独分区压力,同时 DynamoDB 也会对主键值尝试做“合理的”分区。 在开始我们没有对主键值做任何处理,因为 DynamoDB 会将分区键值作为内部散列函数的输入,其输出会决定数据存储到具体的分区。但随着运行,我们发现数据开始出现写入偏移了,而且非常严重,带来的后果就是导致 DynamoDB 表的读写性能下降,具体原因在后面会做详细讨论。发现这类问题之后,我们考虑了两种解决办法:  所以我们选择了第二种方法,调整业务代码,在写入时将主键值做哈希,查询时将主键条件做哈希进行查询。 自动扩容潜规则 在解决了数据偏移之后读 / 写性能恢复了,但是运行了一段时间之后读写性能却再次下降。查询了数据写入并不偏移,当时我们将写入性能提升到了 6 万 +/ 秒,但没起到任何作用,实际写入速度也就在 2 万 +/ 秒。最后发现是我们的分区数量太多了,DynamoDB 在后台自动维护的分区数量已经达到了 200+ 个,严重影响了 DynamoDB 表的读写性能。 DynamoDB 自动扩容、支持用户任意设定的吞吐量,这些都是基于它的两个自动扩容规则:单分区大小限制和读写性能限制。 单分区大小限制 DynamoDB 会自动维护数据存储分区,但每个分区大小上限为 10GB,一旦超过该限制会导致 DynamoDB 拆分区。这也正是数据偏移带来的影响,当数据严重偏移时,DynamoDB 会默默为你的偏移分区拆分区。我们可以根据下面的公式计算分区数量: 数据总大小 / 10GB 再向上取整 = 分区总数 比如表里数据总量为 15GB,15 / 10 = 1.5,向上取整 = 2,分区数为 2,如果数据不偏移均匀分配的话两个分区每个存储 7.5GB 数据。 读写性能限制 DynamoDB 为什么要拆分区呢?因为它要保证用户预设的读 / 写性能。怎么保证呢?依靠将每个分区数据控制在 10G 以内。另一个条件就是当分区不能满足预设吞吐量时,DynamoDB 也会将分区进行扩充。DynamoDB 对于每个分区读写容量定义如下: 写入容量单位:写入容量单位(WCU:write capacity units),以每条数据最大 1KB 计算,最大每秒写入 1000 条。 读取容量单位:读取容量单位(RCU:read capacity units),以每条数据最大 4KB 计算,最大每秒读取 3000 条。 也就是说,一个分区的最大写入容量单位和读取容量单位是固定的,超过了分区最大容量单位就会拆分区。因此我们可以根据下面的公式计算分区数量: (预设读容量 /3000)+(预设写容量 /1000)再向上取整 = 分区总数 比如预设的读取容量为 500,写入容量为 5000,(500 / 3000) + (5000 / 1000) = 5.1,再向上取整 = 6,分区数为 6。 需要注意的是,对于单分区超过 10G 拆分后的新分区是共享原分区读写容量的,并不是每个表单独的读写容量。 因为预设的读写容量决定了分区数量,但由于单分区数据量达到上限而拆出两个新的分区。 所以当数据偏移严重时,读写性能会急剧下降。 冷热数据 产生上面的问题是由于我们一开始是单表操作。这样就算数据不偏移,但随着时间推移数据量越来越多,自然拆出的分区也越来越多。 因此,我们根据业务做了合理的拆表、设定了冷热数据表。这样做有两大好处: 提升性能:这一点根据上面的规则显而易见,热表中数据量不会持续无限增长,因此分区也稳定在一定数量级内,保证了读写性能。 降低成本:无谓的为单表增加读写性能不仅效果不明显,而且费用也会急剧增高,使用成本的增加对于谁都是无法接受的。DynamoDB 存储也是需要成本的,所以可以将冷表数据存储到 S3 或其他持久化服务中,将 DynamoDB 的表删除,也是降低成本的一种方式。 表限制 (编辑:ASP站长网) |
 MySQL IS NULL如何查
MySQL IS NULL如何查 最简单的创建 MySQL
最简单的创建 MySQL 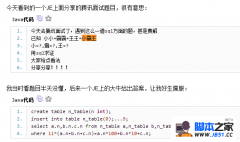 网上看到的给大家分享
网上看到的给大家分享 MYSQL教程MySql 5.6.3
MYSQL教程MySql 5.6.3